From Scratch: Building GPT-2 for Efficient Language Modeling
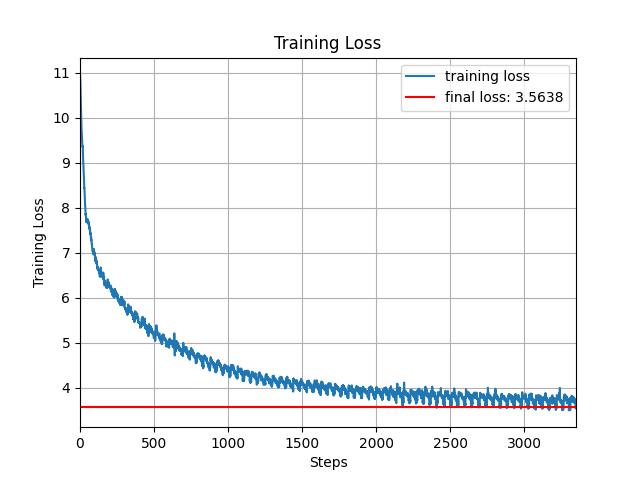
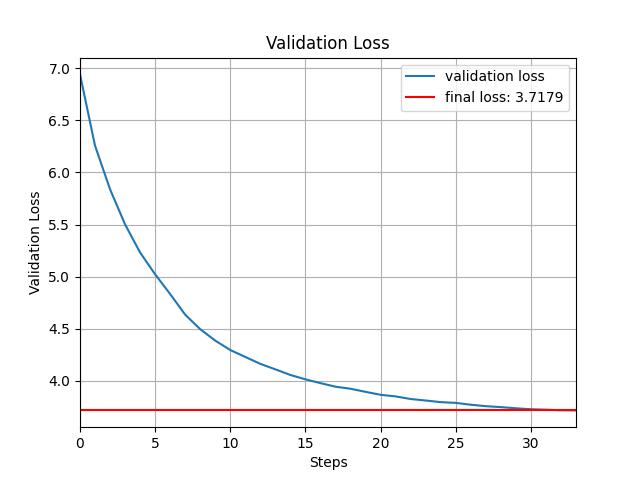
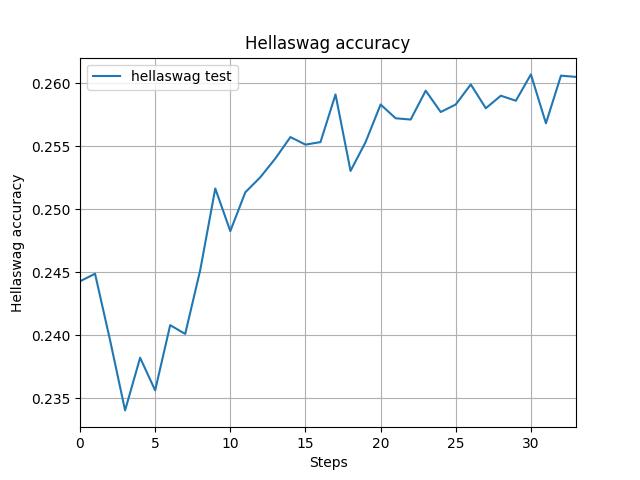
Re-implemented GPT-2 (124M parameters) from the ground up using PyTorch, faithfully reproducing its architecture as introduced in Attention Is All You Need. Core components include tokenization, token and positional embeddings, multi-head self-attention, feed-forward layers, and residual connections. The model was trained on the FineWeb dataset and evaluated using the HellaSwag benchmark. Achieved 26% accuracy on HellaSwag after just 2 days of training on a single NVIDIA A6000 GPU, closely approaching OpenAI’s official GPT-2 score of 28.92%, which required extensive compute on NVIDIA V100 clusters over weeks. This project demonstrates how efficient architectural replication and strategic training schedules—inspired by the original transformer design—can yield near-benchmark performance under significant resource constraints.
Key Features
- Tokenization: Used OpenAI’s tiktoken tokenizer (based on Byte Pair Encoding from Neural Machine Translation of Rare Words with Subword Units), with preprocessing rules to improve handling of contractions, numbers, trailing spaces, non-alphabetic characters, and punctuation.
- Transformer Architecture: Faithfully followed the GPT-2 blueprint:
- Token and positional embeddings.
- Multi-head self-attention with layer normalization and residual connections.
- MLP feedforward block with GELU activations.
- Attention mechanism : Integrated FlashAttention to accelerate training and reduce memory overhead.
- Evaluation: Achieved 26% accuracy on the HellaSwag benchmark (vs. OpenAI's 28.92%) after just 2 days of training on a single NVIDIA A6000 GPU.
Training Setup
| Parameter | This implementation | OpenAI's 124M parameters |
|---|---|---|
| Iterations | 3400 | 19073 |
| Warmup Steps | 132 | 715 |
| Batch Size | 32 | 128 |
| Total Batch Size | 524,288 | 524,288 |
| Sequence Length | 512 | 1024 |
| Vocabulary Size | 50304 | 50304 |
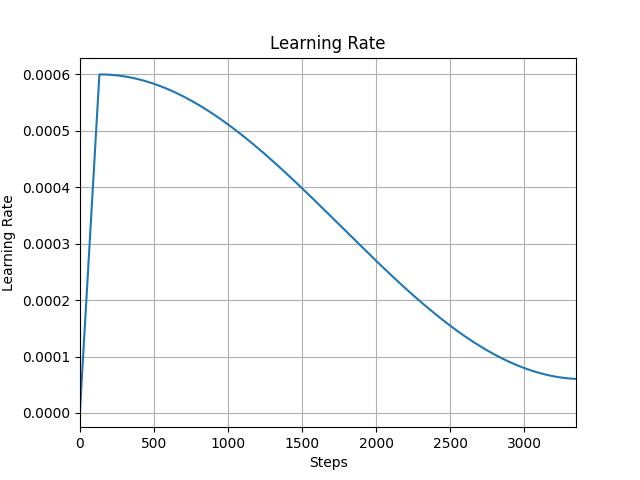
- Learning Rate Schedule: Linear warm-up followed by cosine decay, as used in GPT-3.
- Optimizer: AdamW with β₁=0.9, β₂=0.95, ε=1e-8
Results